扫码分享到微信
【赛迪网讯】当大模型的参数竞赛逐渐触及天花板,产业界悄然达成一个新的共识:决定AI“智商”高低的,不再是单纯的算法堆砌,而是其“消化”的数据质量。3月1日,在第四届北京人工智能产业创新发展大会的“AI+数据要素”分论坛上,这一命题被反复印证——高质量数据集,正从AI的“辅助品”演变为核心“战力”的关键构成。
这场由国家数据局、北京市政务服务和数据管理局指导,北京市门头沟区人民政府、中国电信北京公司、北京邮电大学联合主办的高层对话,并未停留在政策宣讲层面,而是直指一个产业核心痛点:当千行百业拥抱AI,谁来为模型准备好“优质食材”?
政企联动激活区域新动能
数据要素的价值化,首先需要物理空间的承载。京西古道曾是经济走廊,如今的门头沟则试图定义一种新枢纽——数据要素的流通与加工中心。
分论坛上,北京市门头沟区人民政府与中国电信北京公司的战略合作启动,将这一构想推向了实操层面。双方围绕新型信息基础设施、数据要素价值释放、城市安全治理及数字标杆场景四大方向展开深度合作。这并非简单的政企签约,而是一次区域经济的“换道”布局:通过中国电信的数据全链条能力,打通从采集、治理到流通、应用的闭环,将门头沟构建为“数据输入—智能加工—价值输出”的区域节点。
当公共数据与城市治理、产业转型深度嵌合,门头沟的定位愈发清晰——它不仅是地理上的连接点,更是北京建设全球数字经济标杆城市进程中,一个验证数据要素如何赋能实体经济的“中试基地”。
为AI造“粮食”
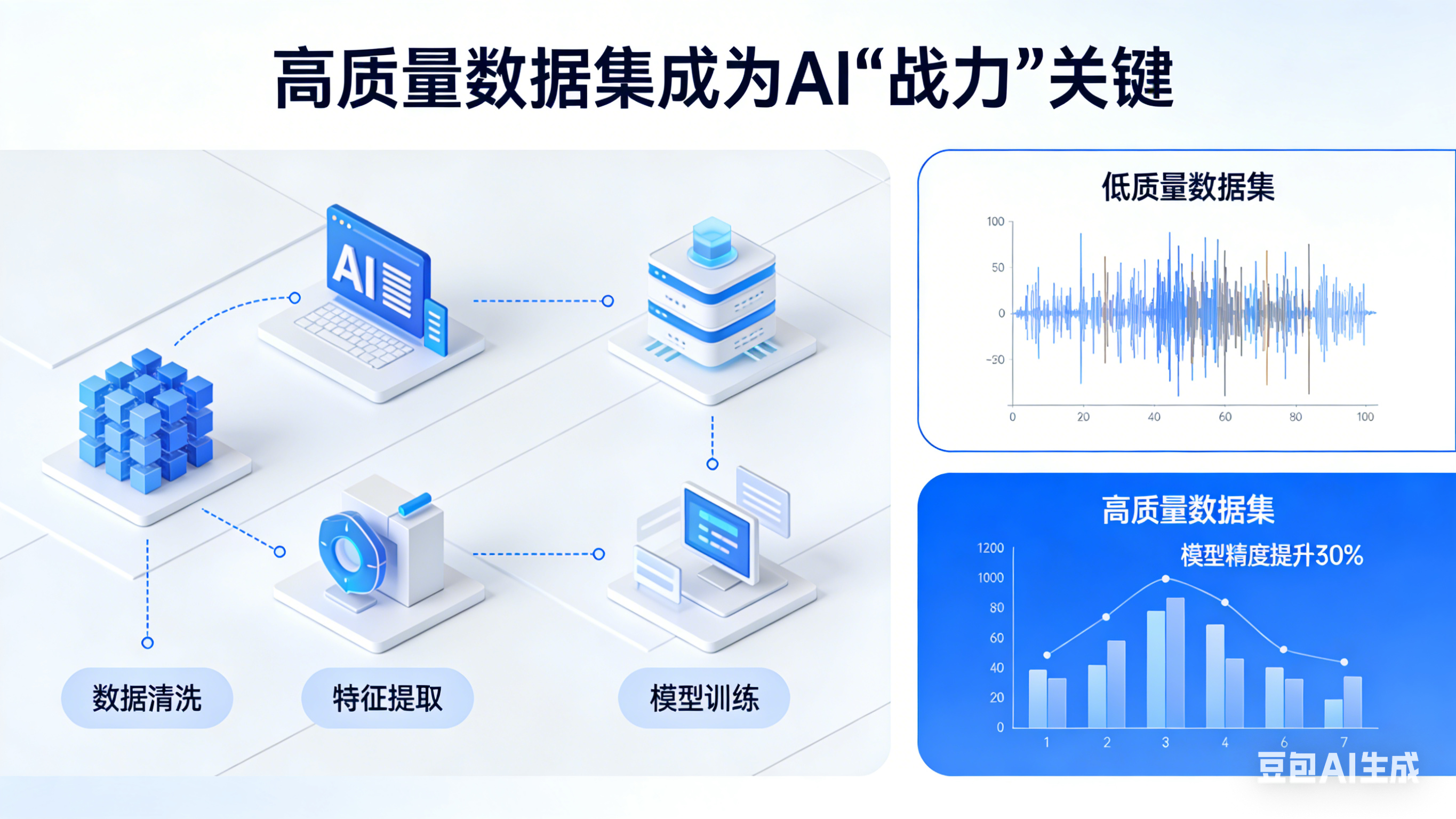
产业智能化面临一个尴尬现实:数据总量爆炸式增长,但算法“能吃”的高质量数据极度匮乏。“体量大、质量低、应用难”成为普遍掣肘。正如业内所言,同样的模型框架,输入高质量数据与输入原始噪声,输出的可能是“学霸”与“学渣”的天壤之别。
为解决这一核心矛盾,中国电信北京公司联合中交信科集团、山东港口青岛港、中科院计算所、北京邮电大学在论坛上发布了“交融高质量数据集平台”。这一动作的本质,是为AI发起一场“造粮”运动。
该平台的产业意义在于,它将数据处理的复杂工序——采集、治理、质检、加工——封装为标准化服务。通过多模态融合管理与高精尖算子引擎的双轮驱动,企业无需自建昂贵的数据流水线,即可获得可直接“投喂”模型的AI-Ready数据集。这种“开箱即用”的模式,大幅降低了行业大模型落地的门槛。
目前,该平台已支撑多个国家级及省级高质量数据集先行项目,并在港口全要素调度、安全作业管控等场景实现了数据、模型与业务的深度融合。当数据被精准加工为AI可理解的“养分”,产业智能化的效率瓶颈开始松动。
多模态实验室筑牢产业底座
如果说“交融”平台解决的是当下的应用之急,那么面向未来的技术壁垒,则需要更底层的攻坚。
论坛上,由中国电信北京公司与北京邮电大学联合申报的“多模态数据智能感知与治理北京市重点实验室”正式揭牌。该实验室聚焦于AI时代数据价值化与安全治理的根本矛盾——既要让异构数据“说同一种语言”,又要在流通中实现安全可控。
实验室锁定的四大方向——多模态数据融合理解、智能关联分析、安全管控与可信流通,剑指数据要素市场化进程中的关键技术瓶颈。从异构模态的语义鸿沟,到敏感信息的隐私保护,再到数据资产的精准估值,这些基础研究的突破,将决定数据能否真正从“资源”转化为可信、可流通的“资产”。
论坛的深层价值,在于串联起了数据要素价值化的完整逻辑链。从国家信息中心对中国数据要素市场化配置改革的顶层思考,到中国电信构建“高质量数据集到可信流通”价值闭环的产业实践;从中国信通院对建设运营路径的系统梳理,到高校学者对数据标注基础工作的前瞻剖析——理论与实践的对话,最终落地于垂直领域的企业案例。龙湖千丁数科、北京昊睿数创、数新智能等企业的分享表明,数据要素的价值释放,已从宏大叙事走向了具体的业务场景。
面向未来,随着京西数据枢纽的成型、“交融”平台的推广以及重点实验室的技术攻关,数据要素的流通路径正变得愈发清晰。让AI“吃”得好,产业智能才能长得壮。当数据真正打破孤岛、高效流动,数字经济的下一程,才刚刚开始。