扫码分享到微信
短视频搜索业务是向量检索在工业界最核心的应用场景之一。然而,当前业界普遍采用的“自强化”训练范式过度依赖历史点击数据,导致系统陷入信息茧房,难以召回潜在相关的新鲜内容。针对当前挑战,快手搜索团队提出了CroPS框架,从根源上打破数据闭环。目前,CroPS已在快手搜索业务中实现全量部署,服务亿级用户。
本工作相关成果《CroPS: Improving Dense Retrieval with Cross-Perspective Positive Samples in Short-Video Search》已被人工智能顶级会议AAAI 2026 Oral接收。

为了打破数据边界,CroPS 框架构建了一个包含三个维度的正样本增强引擎,分别利用用户换Query行为、推荐系统反馈以及大语言模型(LLM)的世界知识,来全方位地丰富语义空间。围绕这一目标,CroPS 分别从查询行为、系统反馈和外部知识三个层面展开。
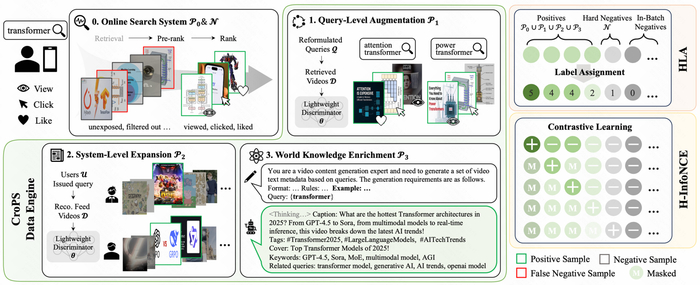
在真实的搜索场景中,用户往往难以一次性精准表达意图。当用户输入查询词A 却未能找到满意结果时,通常会进行查询重构,输入语义相关但表述不同的查询词B。CroPS 通过分析用户在短时间窗口内的改写序列,将改写后获得的成功点击回流给原始查询,利用用户的修正行为来纠正模型的语义偏差。
推荐系统拥有海量用户消费数据,其算法机制天然倾向于发散和探索。CroPS 建立了一套跨系统的信号桥接机制:对于同一个用户,如果他在推荐信息流中深度消费了某个视频,且该视频在语义上与用户近期的搜索词高度相关,该视频就会被引入作为搜索模型的正样本。
当平台现有的内容库或日志无法覆盖某些长尾、复杂查询时,CroPS 引入大语言模型(LLM)作为虚拟检索器和内容生成器,利用 One-shot Prompting 策略生成高质量合成样本,将外部世界的常识与逻辑蒸馏进检索模型中。
在多源正样本被引入之后,如何让模型有效利用这些信号,同样成为训练阶段的关键。HLA 的核心是解决 CroPS 多源正样本的可靠性差异问题,通过为样本分配分层标签,让模型能够学习更细粒度的相关性。H-InfoNCE 在训练时,将当前样本与标签严格低于它的所有样本进行对比,使学习目标与 HLA 的层级逻辑完全对齐。
这一系列设计共同构成了 CroPS 在工业检索场景中的完整解决方案。CroPS 证明了在工业检索系统中,正样本增强是缓解信息茧房问题的有效钥匙。未来,快手搜索团队将进一步探索 CroPS 与生成式检索(Generative Retrieval)方法的融合,持续挖掘大规模语言模型在搜索全链路中的潜力。
2200万用户见证:鸿蒙版WPS凭AI+分布式协同完成办公体验革新
鸿蒙版WPS移动端应用如何塑造了鸿蒙的多端智能办公体验鸿蒙版WPS完成对该机型的深度适配6月HDC 2025成为…
2026-01-14 18:20小艺知识问答重磅升级!无缝联动多款生态应用,打造更懂你的智...
在15-25分钟内就会为你生成结构清晰、数据详实的研究文档、图文报告或智能PPT生成你的专属研究报告不止日…
2026-01-15 09:02